用了 Claude Code 一段时间后,我发现一个很容易被忽略的问题:
刚开始时我只把 Claude Code 当成“更聪明的代码补全工具”,却没有认真维护它的项目上下文。
尤其是CLAUDE.md。
通过一些文章、项目经验,我逐渐总结出来一些使用经验。
1.CLAUDE.md是什么
刚开始我也以为,CLAUDE.md 就是一个可以随便写点项目说明的 Markdown 文件。后来才意识到,它其实更像是写给 Claude 的“项目入职手册”。
它和README的区别在于,README是给人看的,可以写很多,很详细,包括项目介绍、快速入门、开源贡献等等,因为人类可以有选择的去读,且Claude 默认不会主动去读 README,你不告诉它去看,它就当不存在。CLAUDE.md才是那个被自动加载、每次都吃 token 的「默认配置」。
通过一小段 Claude Code 源码可以发现背后的机制:
从你当前所在的目录一路往上爬到文件系统根目录,每爬一层就把目录名记下来。爬完之后再反向遍历,从根目录往下读每一层的 CLAUDE.md 和 .claude/CLAUDE.md,全部合并喂给模型。
const dirs: string[] = []
const originalCwd = getOriginalCwd()
let currentDir = originalCwd
while (currentDir !== parse(currentDir).root) {
dirs.push(currentDir)
currentDir = dirname(currentDir)
}
所以一个项目可能同时有好几份 CLAUDE.md 在生效。它的特殊之处在于:它不是文档,是配置,是你给 Claude 配的「这个项目的预设」。
2.写得越多,效果反而越差
我刚开始用 Claude Code 的时候,是这么想的:CLAUDE.md 多写点总没坏处,规则越细,Claude 越知道我要啥。
后来看到一组数据,这个数据来自一个叫 SFEIR Institute 的技术博客。他们做了一组实测:把所有规则塞在一个 CLAUDE.md 里,控制在 200 行以内的时候,规则遵守率大概 92%。但写到 400 行往上,遵守率就肉眼可见地往下掉。但如果你把 200 行拆成 5 个 30 行的模块化文件,丢到 .claude/rules/ 目录里,遵守率反而能涨到 96%。
原因在于如下两个点:
-
token 经济:CLAUDE.md 每次启动都会被完整加载进上下文窗口。你写 400 行,每次请求就消耗几千 token,挤压你的对话、Claude 的思考、工具调用结果的位置。
-
注意力稀释。模型的注意力不是无限的,规则一多,每条规则在模型脑子里的权重就被摊薄了。所以CLAUDE.md 超过 300 行之后,「记不住」就变成常态。
那么哪些东西该往CLAUDE.MD里写,哪些不该写,就值得去深究了。
首先来看最典型的三类反例:
第一类,复述型。 把整个项目架构文档复制粘贴进 CLAUDE.md,一写写 100 行。问题是项目架构会变,今天 React,半年后可能就 Vue 了,CLAUDE.md 里的 100 行还停留在 React 时代。正确做法是一行话指过去:「项目架构详见 docs/architecture.md」,Claude 真要看自己会去 read。
第二类,愿望型。 「我们希望测试覆盖率达到 90%」、「我们的目标是 0 bug」。这种话听着政治正确,但 Claude 没法判断「希望」和「实际」的差距,可能为了「满足愿望」给你乱补一堆没意义的测试。CLAUDE.md 里只写当下实际执行的规则,「PR 提交前必须跑 npm test」是规则,「我们希望大家多写测试」是 PUA。
第三类,术语表型。 把团队术语表往 CLAUDE.md 里搬。「Repo 指 repository、PR 指 pull request……」Claude 是个 LLM,这些通用术语它都懂。你真正需要解释的是团队特有的黑话(比如「我们说『小灰』指的是预发布环境」),但也建议放 docs/glossary.md 里。
3. 什么样的规则才是真正有效的
首先举个例子:
同样讲缩进,下面哪种写法 Claude 听得更好?
- A:「所有 TypeScript 文件用 2 个空格缩进」
- B:「代码要按规范格式化」
答案显而易见是A,但为什么呢?
关键差异在一个词:可验证。
A 是具体的,Claude 写完代码自己就能数:是不是 2 个空格?是不是 TypeScript 文件?这两个问题都有明确答案,它能自检。
B 是模糊的,什么叫「按规范格式化」?这个判断需要外部标准,Claude 只能猜你的偏好,猜得对就对,猜得错就错。
所以关于「啥样的规则才有效」,可以浓缩成一句话四个原则:
短、具体、告诉为什么、持续更新。
-
**短:**呼应 200 行的黄金线
-
具体:即上述A和B的差距
-
告诉为什么:这是四条里看着最像废话但是却最关键的一条。比如你写「不要在测试里写入生产数据库」,Claude 知道不能写生产库就完了。但你加一句「因为去年有次测试不小心把 users 表清空了,出过事故」,Claude 不光知道这条规则,还知道规则的边界。这样以后你跑预发布环境(staging)测试,问它能不能写预发布数据库,它会基于「规则的本质是防生产事故」做出正确判断,而不是机械地说「规则说了不能写数据库」。
所以告诉「为什么」不是废话,是给 Claude 留判断空间。
- 持续更新:就是把 CLAUDE.md 当活文档维护,Claude 在哪儿犯错了两次以上,你就加一条防御规则。但同样重要的是:老规则要删。
正如claudeguide.io中的一句话所言:「错误的规则比没有规则更糟。」
4. CLAUDE.md 不只是一个文件
我原本默认CLAUDE.md 就是项目根目录下那一个文件,但实际上,CLAUDE.md 是分层的。
一个项目可能有好几份 CLAUDE.md 同时在生效。
就像第一节的源码描述的一样:从你的工作目录一路往上爬,每一层都尝试读 CLAUDE.md 和 .claude/CLAUDE.md,全部合并喂给模型。
所以一份完整的 CLAUDE.md 生态长这样:
- 项目根的 CLAUDE.md:写整个项目的通用约定(技术栈、目录、命令、硬约束),每次启动都加载,是大头。
- 子目录的 CLAUDE.md:比如前端
frontend/CLAUDE.md写组件约定。这层按需加载,Claude 工作到该目录才生效,不污染整个项目上下文。 ~/.claude/CLAUDE.md全局:跨项目的个人偏好(比如「永远用中文回复」、「我喜欢 4 空格缩进」),相当于给所有 Claude 打了同一份补丁。
以一个前后端分离项目的目录距离,这个项目的CLAUDE.md可能长这样:
~/.claude/
└── CLAUDE.md # 全局:用中文回复我、commit message 写中文
my-project/
├── CLAUDE.md # 项目根:技术栈、目录结构、命令、硬约束
├── frontend/
│ ├── CLAUDE.md # 前端模块:组件用函数式、状态管理用 Zustand
│ └── src/
└── backend/
├── CLAUDE.md # 后端模块:API 用 RESTful 风格、错误统一抛 AppError
└── src/
启动 Claude Code 的时候,根目录的 CLAUDE.md 和 ~/.claude/CLAUDE.md 会自动合并加载。等你让 Claude 改 frontend/ 里的代码,它才会顺手把 frontend/CLAUDE.md 也读进来。改后端代码时,前端那份规则压根不会进上下文,节省 token。
除此之外,还有更进阶的用法:.claude/rules/目录
这是 Claude Code 提供的「模块化 CLAUDE.md」机制。你不在 CLAUDE.md 里堆所有规则,而是在 .claude/rules/ 目录下每个主题一个文件。
比如,你的 .claude/rules/ 目录可能长这样:
.claude/
└── rules/
├── testing.md # 测试规则
├── api-design.md # 接口设计规则
├── security.md # 安全规则
└── ui-components.md # UI 组件约定
同时,每个 rules 文件可以加一段 YAML frontmatter(写在文件最顶部、用 --- 包起来的一段元信息),标注「这规则只在改某类文件的时候加载」。比如 testing.md 长这样:
---
paths: ["**/*.test.ts", "**/*.spec.ts"]
---
# 测试规则
- 用 describe / it,不用 test()
- mock 外部依赖必须用 vi.mock
- 每个测试只写一个断言
- 别用 expect.anything(),断言要精确
rontmatter 里的 paths 告诉 Claude:「这条规则只在改测试文件时才加载」,改业务代码时根本不会碰这条规则
同理,api-design.md 顶部可以写 paths: ["src/api/**/*.ts"],Claude 只在改接口代码时才加载:
---
paths: ["src/api/**/*.ts"]
---
# 接口设计规则
- 所有接口走 RESTful 命名(GET / POST / PUT / DELETE)
- 返回值统一用 { data, error } 格式
- 错误码用 4 位数字(如 1001、1002),别用字符串
这叫 path-scoped rules(路径作用域规则)。Claude 只在工作到匹配路径的文件时才把这份规则加载进上下文。改业务代码的时候根本看不到测试规则,改接口的时候也不会看到 UI 组件约定,省下来的 token 全留给真正有用的对话。
打个比方,公司有总公司手册、各部门有部门手册、每个岗位有岗位手册。你不会让每个新人都把所有手册随身带着,对应业务的时候才翻对应的手册。
有海外开发者的方案把这套生态推到了极致:
CLAUDE.md 起步;长了拆
rules/;高频工作流写到commands/;可复用能力封装成skills/。
CLAUDE.md 只是入口,后面还有 commands(自定义命令)和 skills(可复用能力包)两套机制。

那如果用Codex也可以实现这种效果吗?
当然可以。
Codex 那边也有一份自己的「团队约定」,只不过文件名不叫 CLAUDE.md,叫 AGENTS.md。
它的作用、写法、加载机制跟 CLAUDE.md 几乎一模一样。前面的所有原则,200 行黄金线、具体可验证、告诉 为什么、持续更新,照搬到 AGENTS.md 里就行。
如果同时使用Claude Code和Codex,那便有一个取巧的做法:
把所有规则写在AGENTS.md里,CLAUDE.md只写一条:
@AGENTS.md
CLAUDE.md 里的 @文件名 是个引用指令。Claude Code 启动加载 CLAUDE.md 时,看到 @AGENTS.md,会顺着这条引用把 AGENTS.md 的内容也读进来;Codex 那边本来就直接读 AGENTS.md,规则自然也拿到。
但是有一个坑还是要注意:规则之间会打架。
官方文档原话:「如果两条规则互相矛盾,Claude 可能会随便挑一条。」但模型没法判断哪条优先级更高。所以分层之后,得定期 review,把过时的、冲突的规则清掉。
5./init 起步、/memory 维护
那么CLAUDE.md写完以后,怎么把它跑起来。
CLAUDE.md 并不是自动创建的,而是需要我们自己手动创建的。
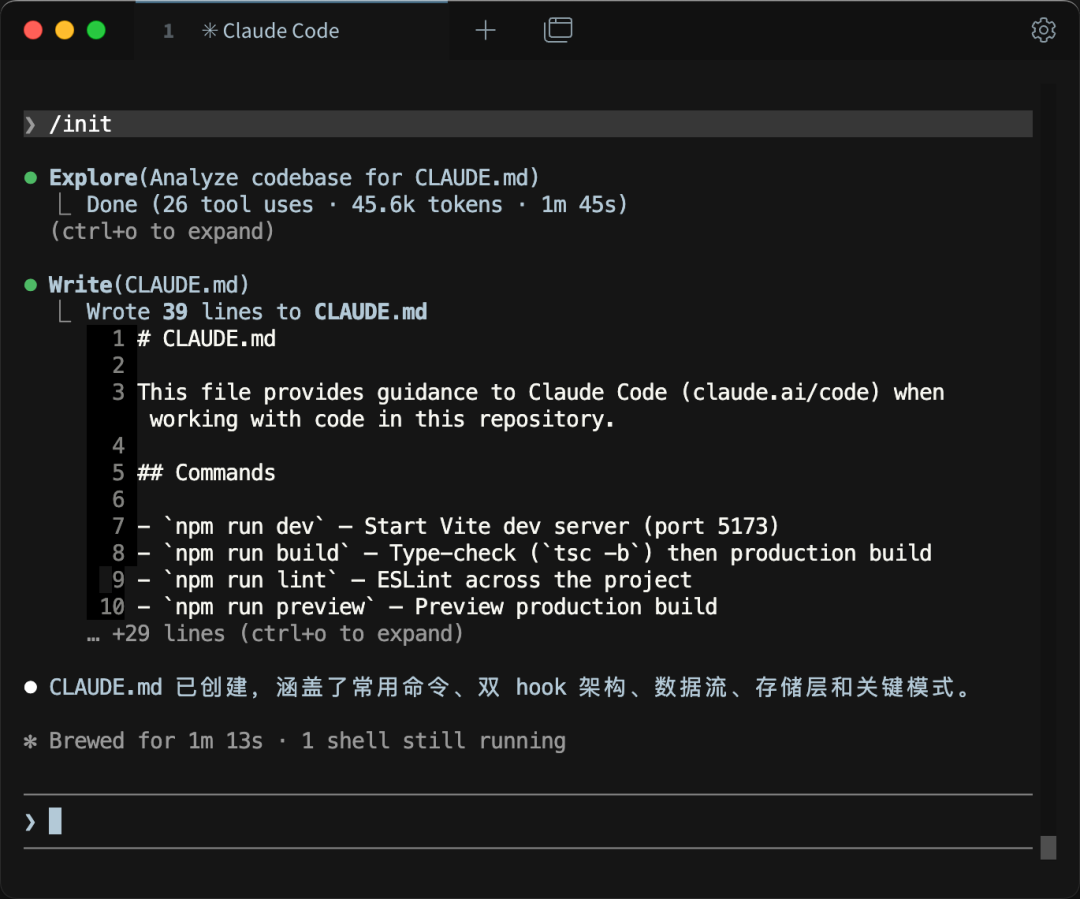
如果你项目里压根还没 CLAUDE.md,第一步需要先/init 。
在 Claude Code 里输入 /init,Claude 会自动扫一遍你的代码库,把分析出来的技术栈、目录结构、常用命令起个草稿。Anthropic 官方文档里有句话:「五分钟时间,永久受益。」
然后review 一遍删掉不准的、补上漏掉的,起点已经比从空文件开始高出几个台阶。
项目跑起来之后,规则怎么补充?最经典的工作流是这样:Claude 在哪儿犯错了,就加一条防御规则。
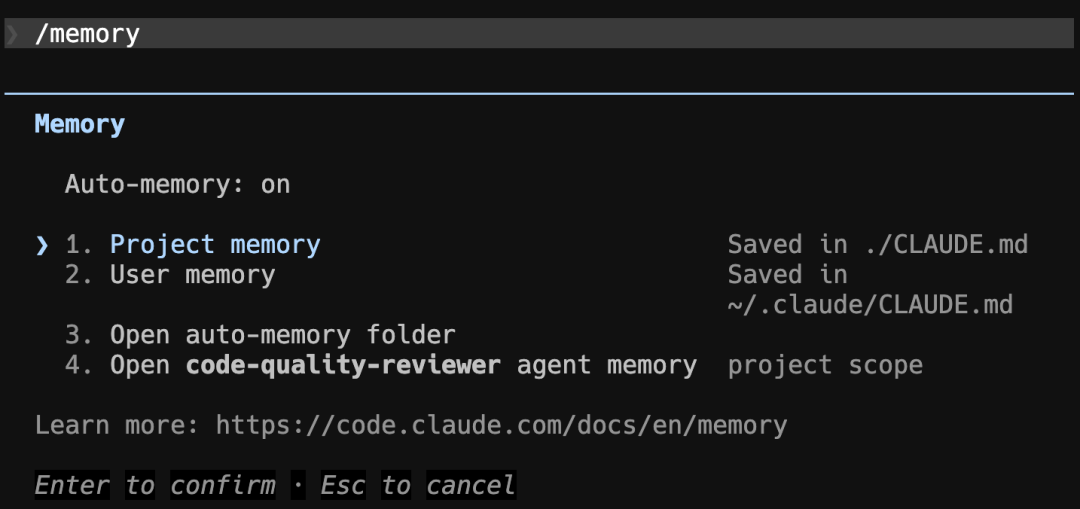
但你不需要手动打开 CLAUDE.md 编辑,Claude Code 提供了 /memory 命令。
session 中途想加规则,直接输入 /memory 会弹出 CLAUDE.md 让你直接改。或者你跟 Claude 说一句「记一下这条规则」,它会自动追加到合适的 CLAUDE.md 文件里去。
claudeguide.io 给了一个特别实用的规则触发标准:Claude 错两次以上,就加一条新规则。 一次可能是偶发,两次说明规则有缺。再不写就会一直被它坑。
还有一个常被忽略的命令配合:Plan Mode。
复杂任务的时候,按 Shift+Tab 两次切到 Plan Mode,Claude 不直接动手写代码,而是先出一份计划给你看,确认了再执行。
Plan Mode 出计划的时候,会把你 CLAUDE.md 里的规则全考虑进去。一份好的 CLAUDE.md 直接决定了计划的质量,计划出得好不好,决定了最终代码写得对不对。
6.参考模板
这套结构参考了 claude-codex.fr 技术博客里的 6 段式建议,然后稍微做了精简:
# CLAUDE.md
## 1. Project Overview
(2-3 行讲清这是个啥项目,技术栈 + 定位)
- 这是一个面向 B 端的订单管理系统
- 技术栈:TypeScript + Next.js 14 + PostgreSQL
- 部署:Vercel + Supabase
## 2. Commands
(最常用的几个命令,Claude 会直接执行)
- 安装依赖:`pnpm install`
- 启动开发:`pnpm dev`
- 跑测试:`pnpm test`
- 类型检查:`pnpm typecheck`
- Lint:`pnpm lint`
## 3. Architecture
(三句话讲完架构,不要展开)
- 前端页面在 app/(App Router)
- API 路由在 app/api/
- 数据库 schema 在 prisma/schema.prisma
- 详细架构见 docs/architecture.md
## 4. Conventions
(团队真实在用的约定)
- 组件文件用 PascalCase(UserCard.tsx)
- 工具函数用 kebab-case(format-date.ts)
- API 返回统一用 { data, error } 格式
- 错误处理用 Result type,不要 throw
## 5. Hard Constraints
(这部分要严,Claude 越界一次就要补)
- 不要写入 production 数据库(去年事故)
- 不要修改 prisma/migrations/ 下已经合入的 migration
- 不要把 .env 文件加入 git
- 所有 API 路由必须过 requireAuth() middleware
## 6. Gotchas
(每个新人都踩过的坑)
- 跑 dev 之前要先 pnpm db:push 同步 schema
- macOS 上 Prisma 偶发崩溃,重启 dev server 就好
- Vercel 部署日志在 dashboard 里看,不在终端
总结
第一,CLAUDE.md 是给 Agent 的“入职手册”,不是给人的 README。写之前先问自己:这句话是给人看的,还是给 Claude 看的?给人看的留给 README。
第二,200 行是黄金线,每行都吃 token,多写不如不写。复述型、愿望型、术语表型这三类内容直接删,瘦下来 Claude 反而更听话。
第三,具体可验证、告诉 why、持续更新,三条铁律压过一切技巧。
最后写一点我的简单理解总结:
「CLAUDE.md 每次启动都会被完整加载进上下文,规则一多反而稀释模型注意力。社区实测数据是 200 行 92% 遵守率,400 行掉到 70%。我的做法是项目根 CLAUDE.md 控制在 80 行以内,按模块拆到
.claude/rules/下用 path-scoped 加载,配合/init起步和/memory维护,规则遵守率明显上来了。」
